This week I’ll be discussing generalization and overfitting, two important and closely related topics in the field of machine learning.
However, before I elaborate on generalization and overfitting, it is important to first understand supervised learning. It is only with supervised learning that overfitting is a potential problem. Supervised learning in machine learning is one method for the model to learn and understand data. There are other types of learning, such as unsupervised and reinforcement learning, but those are topics for another time and another blog post. With supervised learning, a model is given a set of labeled training data. The model learns to make predictions based on this training data, so the more training data the model has access to, the better it gets at making predictions. With training data, the outcome is already known. The predictions from the model and known outcomes are compared, and the model’s parameters are changed until the two align. The point of training is to develop the model’s ability to successfully generalize.
Generalization is a term used to describe a model’s ability to react to new data. That is, after being trained on a training set, a model can digest new data and make accurate predictions. A model’s ability to generalize is central to the success of a model. If a model has been trained too well on training data, it will be unable to generalize. It will make inaccurate predictions when given new data, making the model useless even though it is able to make accurate predictions for the training data. This is called overfitting. The inverse is also true. Underfitting happens when a model has not been trained enough on the data. In the case of underfitting, it makes the model just as useless and it is not capable of making accurate predictions, even with the training data.

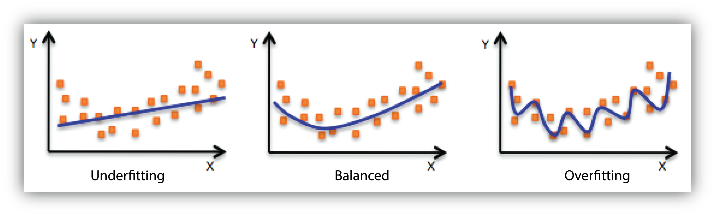
The figure demonstrates the three concepts discussed above. On the left, the blue line represents a model that is underfitting. The model notes that there is some trend in the data, but it is not specific enough to capture relevant information. It is unable to make accurate predictions for training or new data. In the middle, the blue line represents a model that is balanced. This model notes there is a trend in the data, and accurately models it. This middle model will be able to generalize successfully. On the right, the blue line represents a model that is overfitting. The model notes a trend in the data, and accurately models the training data, but it is too specific. It will fail to make accurate predictions with new data because it learned the training data too well.
Next week, I will discuss the specifics of gathering data, formatting data to fit the needs of a model, and different ways to represent data. Data is what a machine learning model uses to make predictions for new situations. It is great to have a model, but without data for the model to interact with, the predictions the model make will be useless.
Photo is titled “mlconcepts_image5” and was created by Amazon. It is available at http://docs.aws.amazon.com/machine-learning/latest/dg/images/mlconcepts_image5.png
{kind=link}