This week I’ll be concluding this series of machine learning blog posts. Machine learning is quickly growing field in computer science. It has applications in nearly every other field of study and is already being implemented commercially because machine learning can solve problems too difficult or time consuming for humans to solve. To describe machine learning in general terms, a variety models are used to learn patterns in data and make accurate predictions based on the patterns it observes.
First, I introduced generalization and overfitting. Both of these topics are tied to supervised learning, which uses training data to train the model. Generalization is when a machine learning model can accurately predict results from data it hasn’t seen before. Overfitting happens when a model learns the training data too well and cannot generalize. Underfitting, the opposite of overfitting, can also happen with supervised learning. With underfitting, the model is unable to make accurate predictions with both training data and new data.
Then, I discussed datasets. With supervised learning, data is separated into three groups: train, dev, and test datasets. The train dataset is used to train the model. The dev dataset is used to test the model during the model’s development, but not during its training. The test dataset is used when the model is complete to see how it reacts to data it has never seen before. I also discussed how to choose relevant fields in a dataset. Sometimes information just isn’t relevant and should not be included in a dataset.
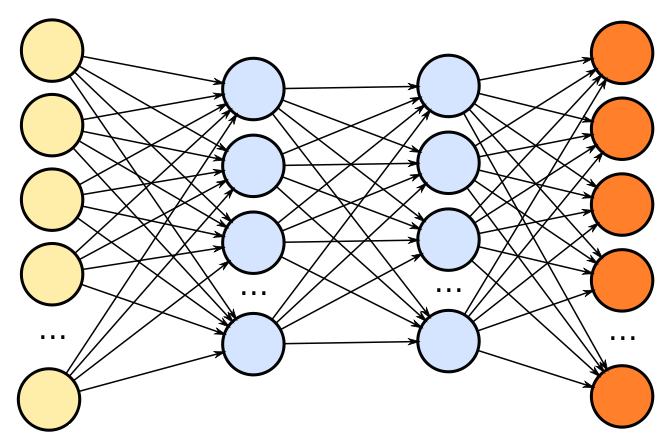
After that, I examined artificial neural networks, the first model in this series of blog posts. Neural networks have three layers: an input, hidden, and output layer. Each layer is made up of nodes. The layers are connected by vectors. Neural networks were one of the first machine learning models to be created, and many variations of neural networks have been explored.
Next, I consider deep neural networks. Where artificial neural networks have a single hidden layer, deep neural networks have multiple hidden layers. Because of the complexity multiple hidden layers adds to the model, deep neural networks are better at some tasks than simple neural networks. However, their added complexity makes them more difficult to train.
Last, I discuss convolutional neural networks. Again, this is a variation of a simple neural network. A benefit to using a convolutional neural network is that it is designed to better handle image and speech recognition tasks. Instead of hidden layers, convolutional neural networks have a convolutional and pooling layer. It is because of these layers that convolutional neural networks are preferred for image and speech recognition.
Thank you for following me on this series of machine learning blog posts. I haven’t even scratched the surface of everything I could talk about with machine learning, but I hope these blog posts have served as an introduction to a few of the topics in this field. It will be exciting to see where machine learning goes in the next 20 years and how it’ll change our lives for the better.

{kind=link}