In the the introduction to this blog, we discussed some of the incredible advances in the field of artificial intelligence in recent years. Using the tic-tac-toe vs. Go analogy for describing problem complexity, we disassembled the traditional “rule-based” approach to creating artificial intelligence and introduced the concept of “bottom-up” learning: a family of algorithms that learn to make decisions based on seeing massive amounts of data and learning by example. The bottom-up paradigm has become the backbone of deep learning, and is almost single-handedly responsible for the more recent A.I. renaissance.
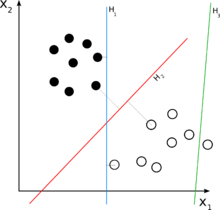
In the first post, we stepped back in time to analyze one the first attempts at creating an algorithm that truly embodied the bottom-up paradigm: Frank Rosenblatt’s perceptron. Though Rosenblatt’s implementation was actually a piece of hardware, it gave birth to the connectionist paradigm and sparked questions about the relationship between the architecture of the perceptron and that of the human brain.
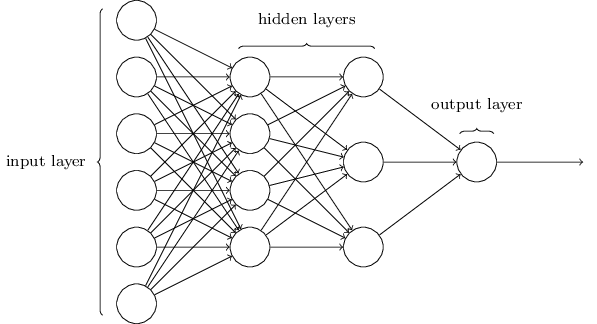
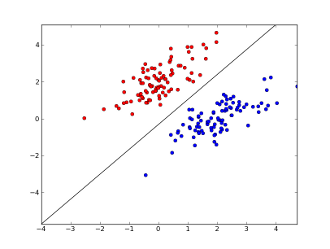
We addressed the issues with Rosenblatt’s perceptron (e.g. lack of hidden layer) in “Neural Networks and Gradient Descent”, and demonstrated how neural networks resolve these problems. We explored the universal approximation theorem, and showed that given enough nodes in a hidden layer, a single hidden layer neural network can theoretically approximate any function. This was a tremendous step forward from the perceptron’s inability to model the XOR function, and we discussed how researchers attempt to optimize neural networks via the gradient descent algorithm.
By the fourth post, “The Genesis of Deep Learning”, we had finally touched on the buzzword, “deep learning”. A natural extension of adding the single hidden layer to Rosenblatt’s perceptron, adding multiple hidden layers in turn added even greater computational power to the neural network. This introduced the need for the backpropagation algorithm, which allowed deep models to efficiently learn just like their shallower parents. With backpropagation we introduced the vanishing and exploding gradient problems, computational graphs, and went into greater detail on gradient descent and how vectors of partial derivatives are applied to weights in a neural network.
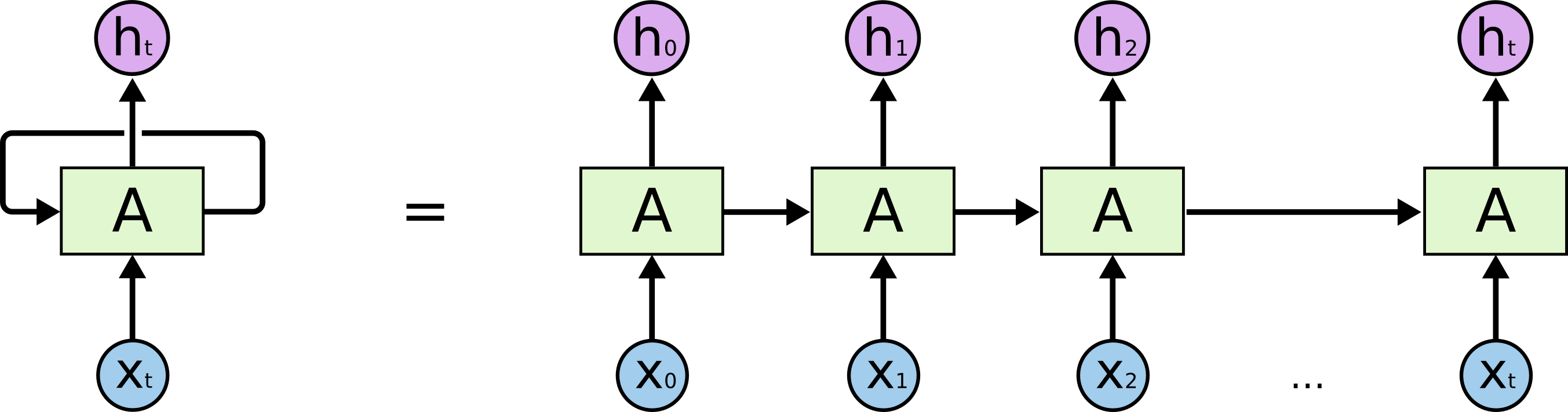
That was still just scratching the surface of what deep learning has really become. In “Learning Through Time”, we introduced a specialized form of deep neural network, the recurrent neural network (RNN). RNNs are fantastic models for processing sequential data, and we discussed how exactly RNNs are able to consume information over time. With the additional dimension of time thrown into the mix, we discussed backpropagation through time, and how training RNNs differs from training vanilla DNNs. We hinted at applications, but didn’t discuss how RNNs are used in modern A.I. applications.
In the last post, we introduced the sequence-to-sequence model (seq2seq), an extension of the RNN, and showed how RNNs can be used to digest sequences, compressing them into single real-valued vectors of arbitrary size. We demonstrated how useful this train can be in natural language processing, where a summary vector can be used to generate incredibly natural-sounding language translations. The seq2seq machine translation algorithm revolutionized Google’s translation service overnight, and is still being improved upon to include a wider variety of languages.
Over the last few weeks, we’ve seen how neural networks evolved over time, starting as simple pattern classifiers and moving on to incredible tasks like language modeling and machine translation. This is far from a comprehensive tour of the world of machine learning, and just scratches the surface of what modern neural networks to do. These models are changing our world every day, and will soon be ubiquitous in our society. Everyone should have at least a basic understanding of the A.I. tools that we use everyday, and I hope that this blog has provided its readers with at least a working knowledge of deep learning.