This week, I will explore data preparation and dataset creation and issues. Data is the blood of the model. Without it, the model cannot learn and make predictions. I will discuss the specifics of gathering data, formatting data to fit the needs of a model, and different ways to represent data.
Before creating a model, one must get data for the model to use. In this day and age, gathering data is not a significant problem. For example, Google gathers data about its users through their searches and their google accounts. It stores documents its users create and personal information users enter when creating their google account. Amazon gathers data from its users whenever they search for or buy something on Amazon’s website. Of course, information about users of a website is not the only data that can be collected. Almost anything can be collected and analyzed. For example, the weather, population, and vehicle traffic are all subjects from which data can be collected.
Once data has been collected, one must determine what data will be used by the model and what data is useless. For example, if a model is being created to predict weather, data about temperature, humidity, and rainfall may be relevant, but data with the names of previous storms is not.
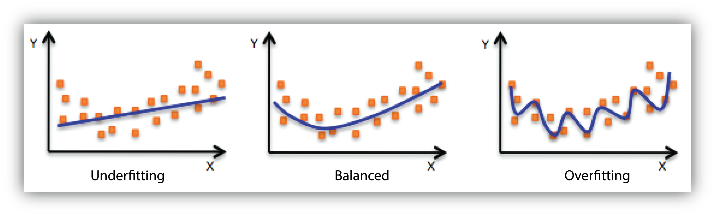
The next step in creating a dataset is the data formatting. With supervised learning, as discussed in last week’s blog post, data needs to be separated into three categories. The first category is training data. This data will be used when training the model, as the name would suggest. The second category is dev data. Dev data is used when developing the model after it has already been trained to evaluate its ability to generalize. Generalization was also discussed in last week’s blog post. The model will probably make predictions on dev data more than once. The third category is test data. This data is used by the model at the end of development. Test data is used to generate publishable results. Since the model has not seen the data in the test category before, the results produced on test data will be an accurate measure of the model’s predictive capabilities.
There are different ways to split the data into train, dev, and test categories and most of the time, it depends on the type of model. Generally, though, more data is put in train than dev or test. The model will be using train data to learn to make accurate predictions, so the more train data it has access to, the better its predictions will be. For example, one could split 50% of the data into the train category, 25% into the dev category, and 25% into the test category.
Next week I will discuss the first model in this series of blog posts, neural networks and some common misconceptions about what they are and are not. Neural networks are one of the more basic models in machine learning, but are still powerful tools and often variations of neural networks are used today.

{kind=link}